


继前文主要解说Ryzen 9000系列、Ryzen AI 300系列处理器与Zen 5、Zen 5c等衍生核心的差异,本为将聚焦于Zen 5、RDNA 3.5、XDNA 2等架构。
Zen 5世代效能再上层楼

▲ Zen 5架构每组核心的L1快取内存配置为32 KB、8路指令快取加上48 KB、12路数据快取,搭载1MB、16路L2快取内存。
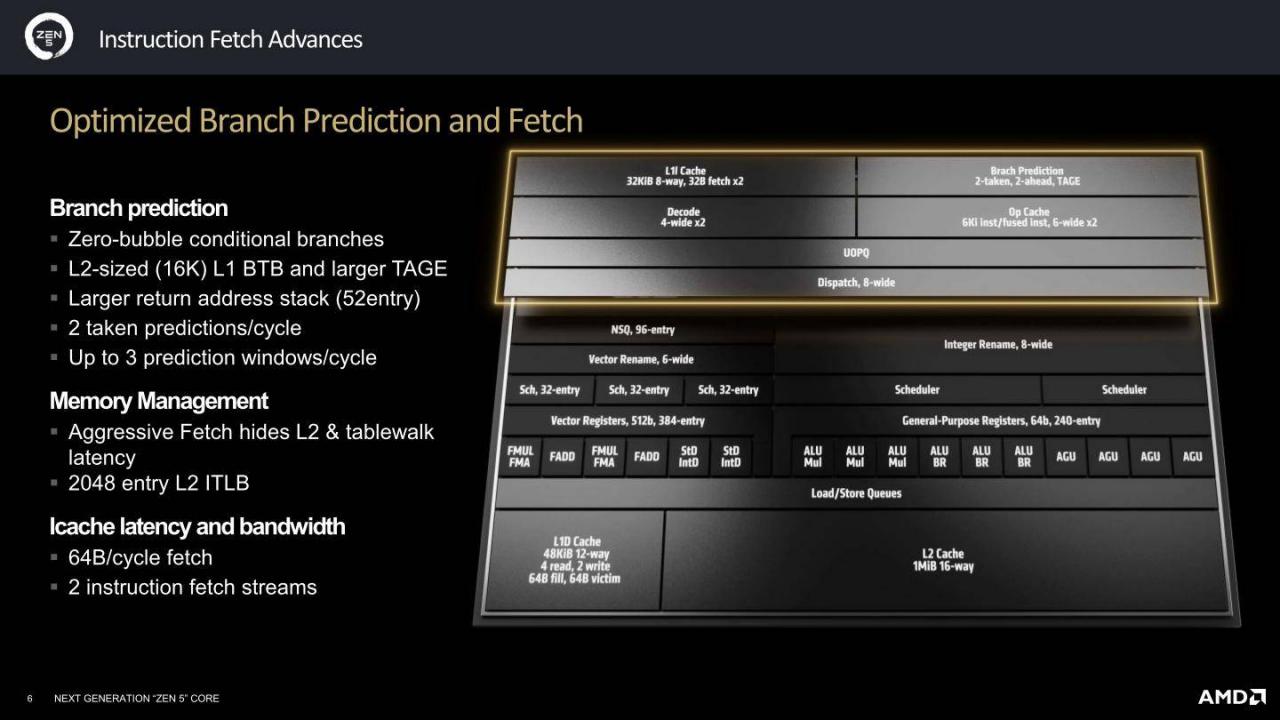
▲ 改良的分支预测机制能在进行条件分支(Conditional Branch)时能达到零空隙(Zero-Bubble)以提生资源利用率,在指令快取部分则具备2组指令预取串流(Instruction Fetch Stream)。

▲ 2组指令预取串流搭配2组指令解码单元,可以同时处理2组独立指令,有助于提升核心内2条执行绪的同时执行效能,强化SMT(Simultaneous Multithreading)多执行绪功能的表现。
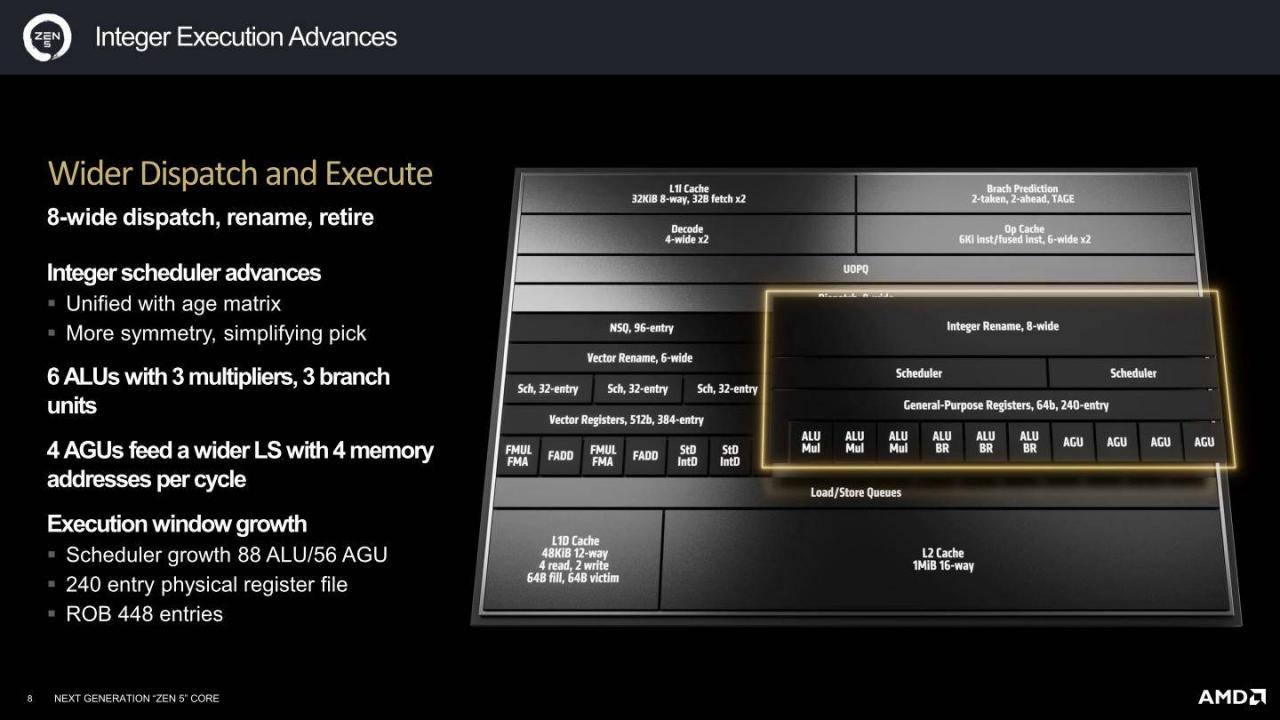
▲ 在整数运算的指派(Dispatch)与执行单元部分,Zen 5搭载8-Wide Dispatch, Rename, Rretire单元,并具有6组ALU(算数逻辑)与4组AGU(内存位置产生)单元。

▲ Zen 5也提升了数据传输带宽,通过增加读取与储存伫列、合并储存缓冲存储器、可扩展读取排序伫列以扩大即时数据窗口,并藉由新增的2D stride预取器改善串流与区域预取的系能。

▲ 在浮点运算部分,最大的改进点在完整支持AVX-512指令集的512 bit资料路径(Datapath),并提供4组执行管线。 相较于前代架构需要3个时钟周期才能完成FADD(浮点加法运算),Zen 5在特定情况下只需2个时钟周期就能完成。
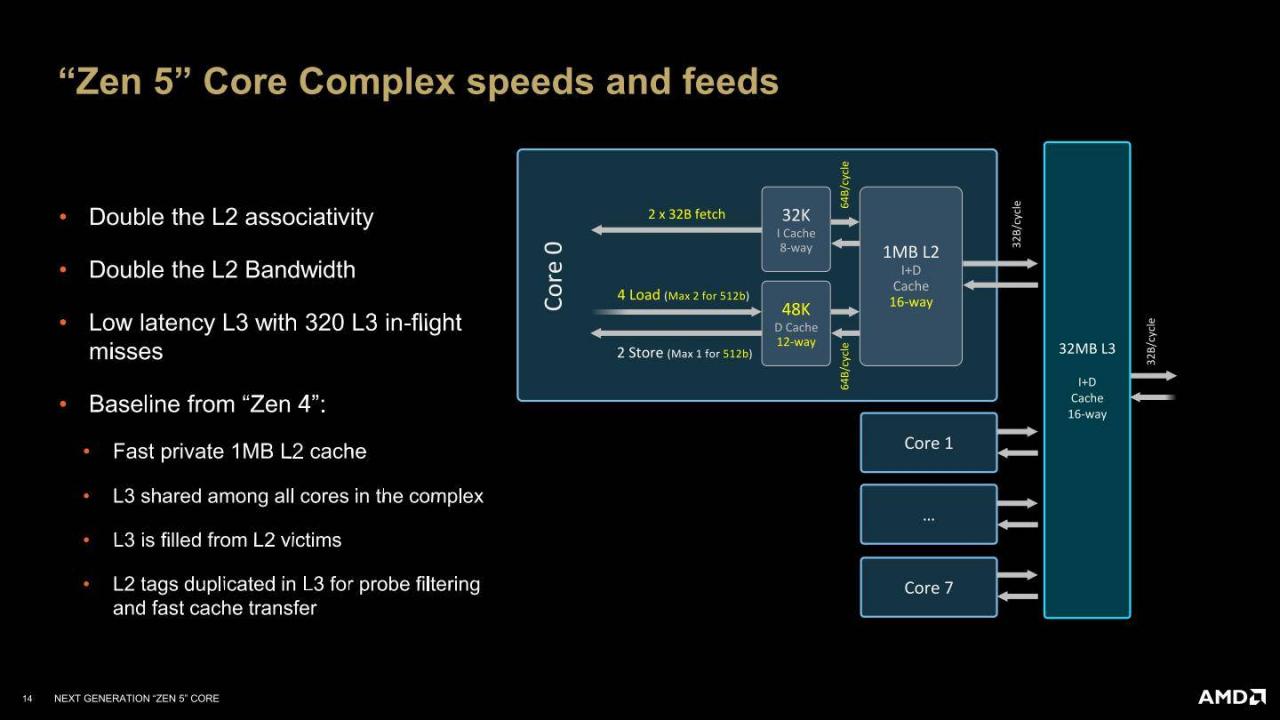
▲ 同CCX(Core Complexes,核心复合体)内的各核心在交换资料时需要通过L3快取内存做为中介。 其运作过程会先查寻储存于L3快取内存内的数据查找表,确认资料存放在哪个核心的L2快取内存,接着发送至L3,再由需要的核心读取进自己的L2。

▲ Zen 5架构新增了许多指令集,例如可以让数据跳过缓存直接写入存储区的MOVIDIRI/MOVD64B,将AVX-512指令扩展至VEX引擎的VNNI/VEX等等。
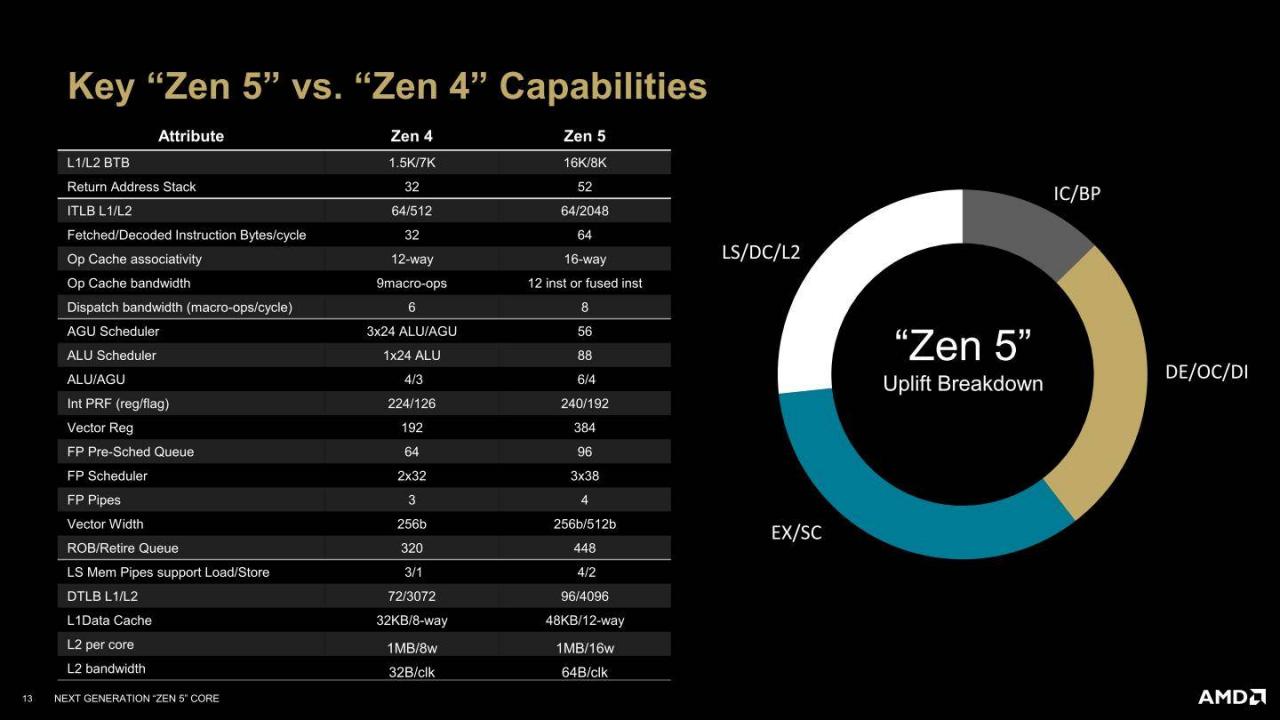
▲ Zen 5与前代Zen 4架构的主要差异对比。
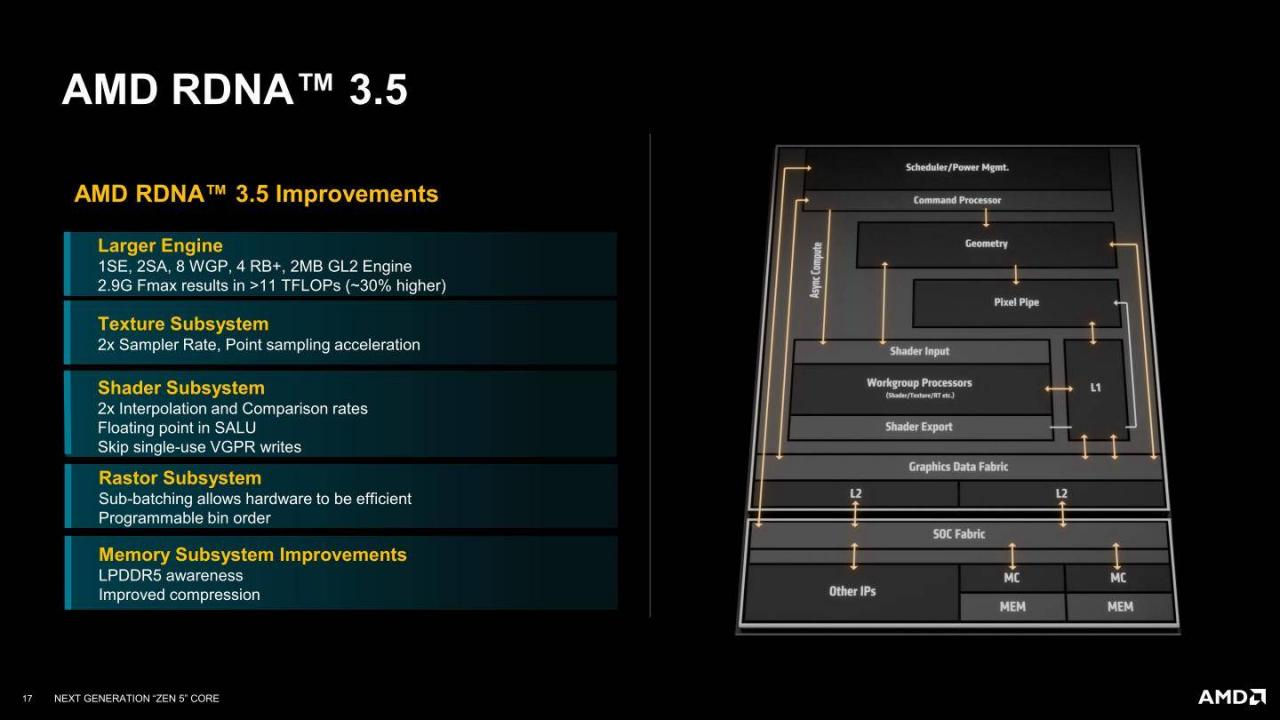
▲ RDNA 3.5绘图架构则是扩大引擎规模,提升2倍材质子系统的取样率、提升2倍渲染子系统的内插与比较率,改善内存的使用效率与资料压缩效率,估计可带来30%的效能增益。
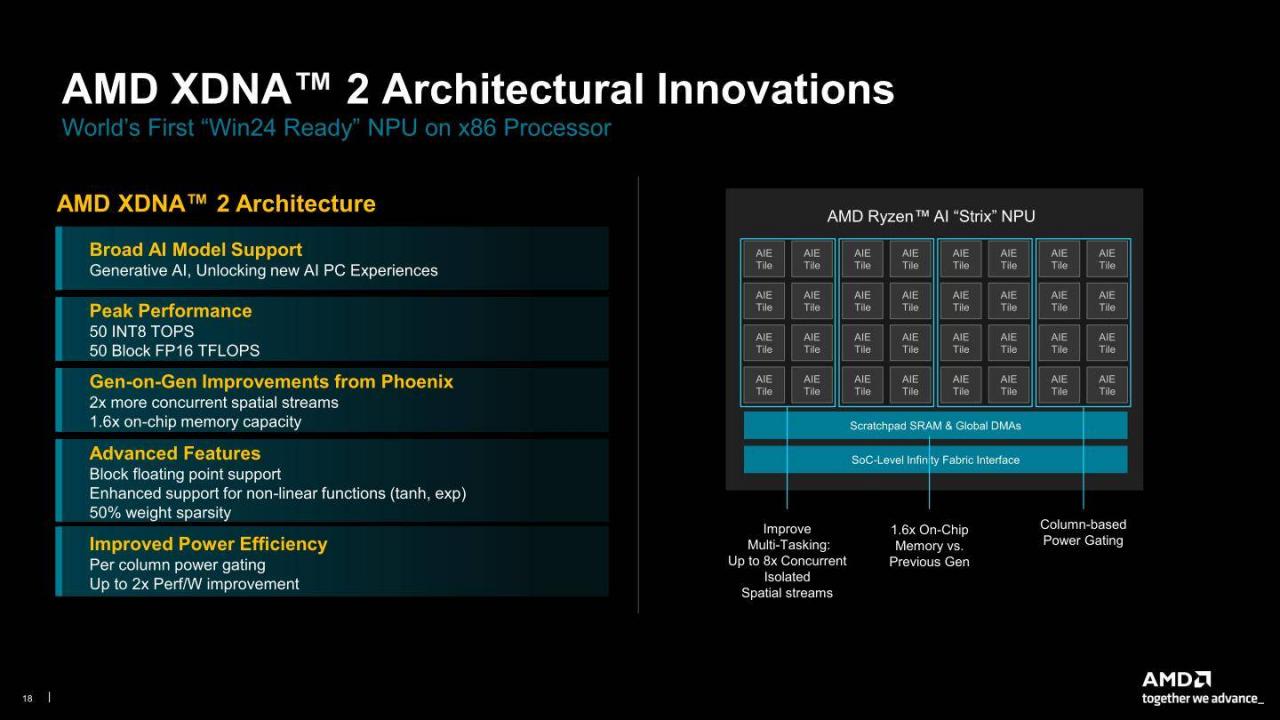
▲ XNDA 2 AI运算架构的主要改善包括增加NPU(神经处理器)内的AI引擎模块(AI Engine Tile)数量,并可支持Block FP16数据类型能够在提供接近FP16的精确度下,享有接近INT8较低的内存占用量以及更高的性能输出。

▲ 总结来说,Zen 5架构再次带来显著效能提升,并通过AVX-512指令集强化AI运算效能,展现AMD持续带来领导地位效能与电力效率的决心。
AMD将Ryzen 9000系列桌上型处理器拆分为2批上市,笔者也会在第一时间带来性能测试专题报导,并更新于本文首的「系列文章」专区。



